
Binary Search Tree
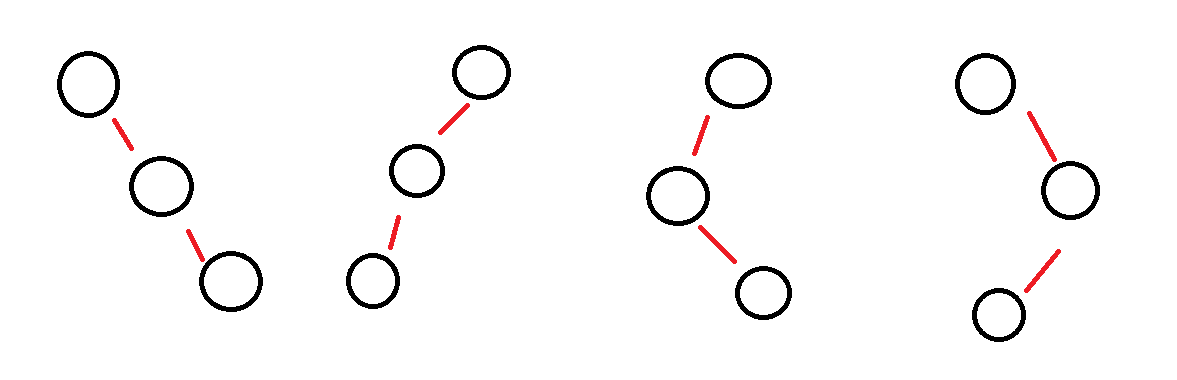
아래 그림과 같이 한 쪽으로 편향될 수 있다.
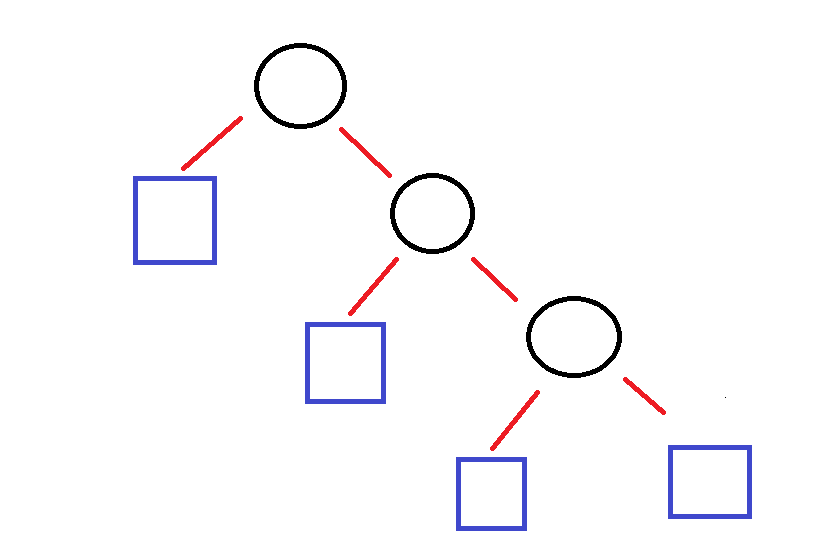
그렇기에 insert, delete, find 함수의 시간 복잡도는 최악의 경우 O(n), 가장 효율적으로는 O(log(n))이 된다.
즉, 높이 h에 따른다는 것을 알 수 있다.
Insert
root부터 해당 value 값보다 작으면 left, 크면 right로 내려가 NULL이 아닐때 까지 탐색
Delete
1. child 중 NULL이 있는 경우
-> external이 아닌 노드를 그대로 이어 붙이면 해결된다.
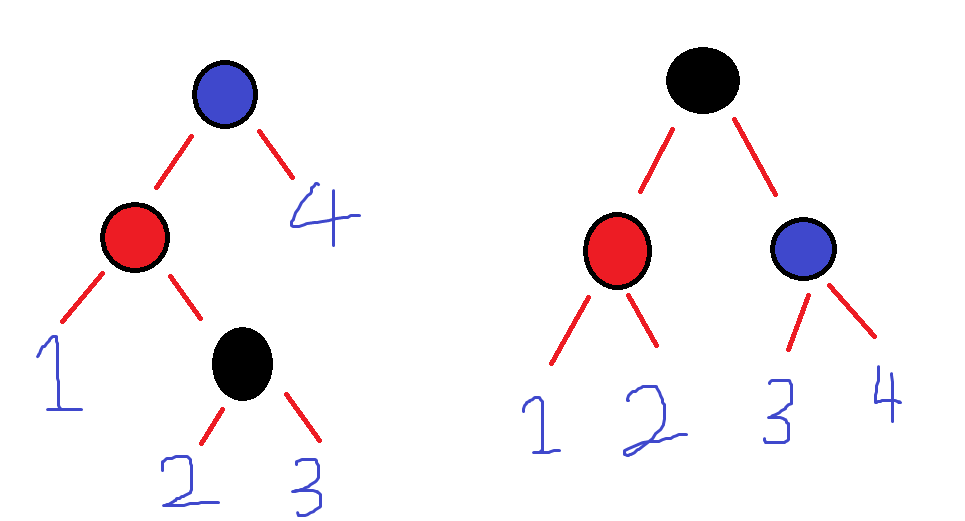
아래 그림은 child에 NULL이 있는 경우인 빨간색 노드를 삭제하는 경우이다.
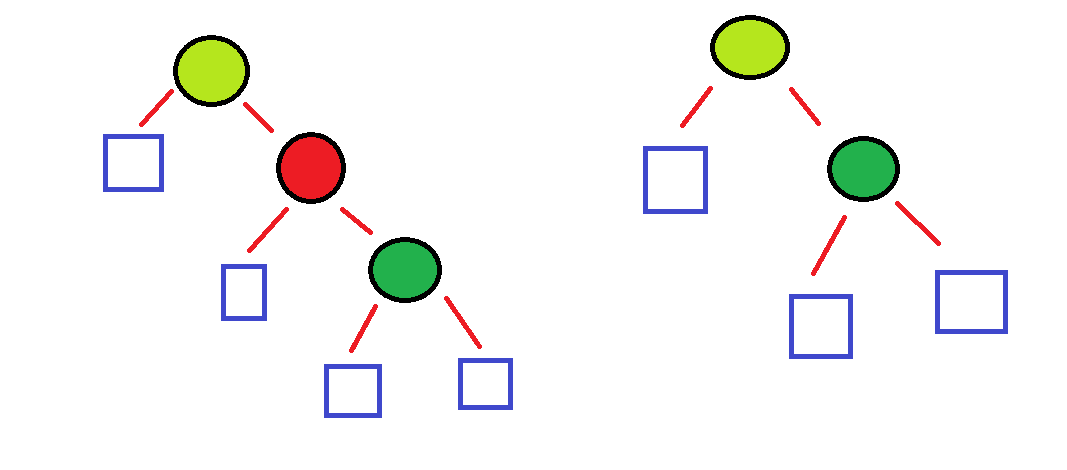
2. 하지만 만약 child 모두 internal 이라면, 얘기가 달라진다.
아래 그림은 internal node인 빨간색을 삭제하는 경우이다.
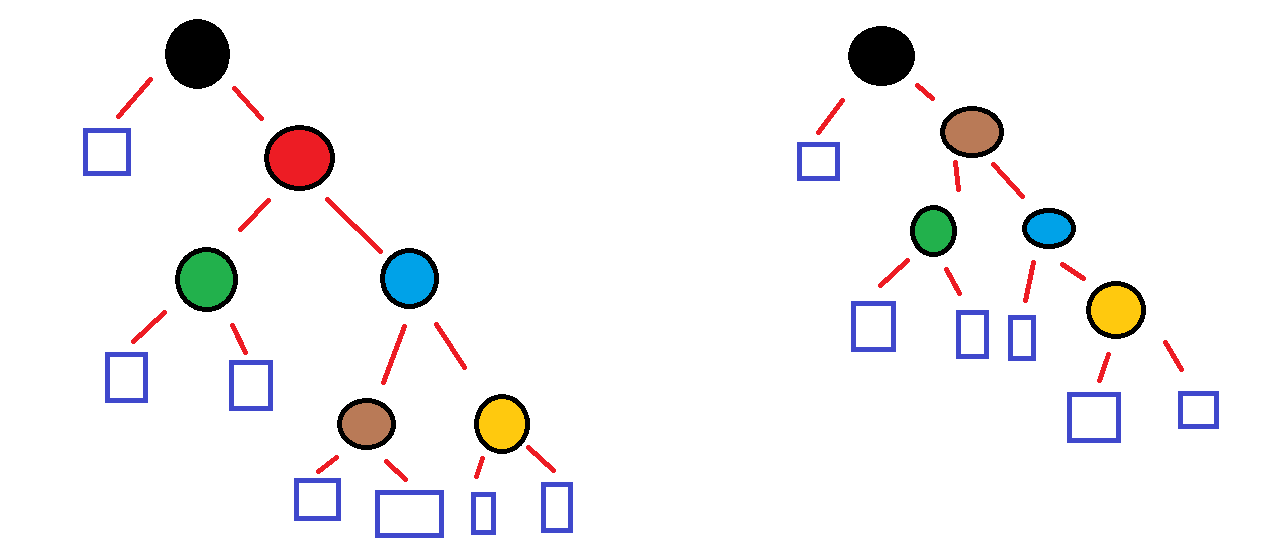
이 경우에는 좀 복잡한데, 이는 heap의 구조와 순서를 다시 맞추어야하기 때문이다.
빨간색을 삭제함과 동시에 초록, 파랑보다 크고, 검은색보다 작은 node를 찾아야하는데,
이를 만족하는 node는 inorder-traversal을 진행하면 알 수 있다.
즉, 빨간색 노드의 right로 내려간 후, NULL이 아닐때까지 left로 내려가면 된다.
간단히 설명하자면,
- successor (가장 유사한 노드)를 먼저 찾고
- 삭제하려는 값에 덮어 씌우고
- successor를 삭제한다.
AVL Tree
BST의 구조가 Complete Binary Tree가 아니기 때문에 시간 복잡도 측면에서 O(n)이 나올 수 있다.
이를 보완하기 위해 Balanced-Binary-Tree를 고안해낸 것이 AVL Tree이다.
이는 자신의 abs(left-child의 높이 - right-child의 높이) <=1인 경우를 만족한다.
가장 깊은 노드는 x-1, x-2, x-3 ...0 으로 감소하지만
반대로 가장 얕은 노드는 x-2, x-4, x-6 ... 으로 감소한다.
즉, 길이는 약 2배 차이난다.
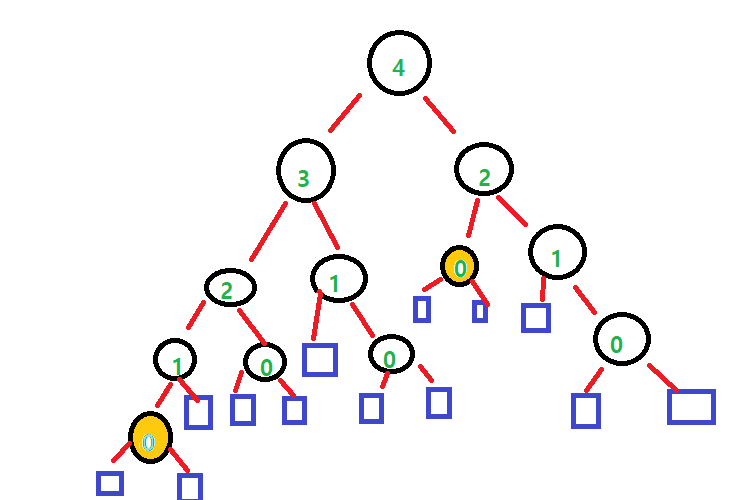
Insert
BST와 마찬가지로 대소 비교 후 External에 추가한다.
하지만 위로 올라가며 두 child의 높이 차가 1이하인지 확인해야 한다.
만약 두 child의 높이 차가 1보다 커지게 되면, 해당 노드를 문제가 발생한 첫 노드라고 판단한다.
그리고 지나왔던 경로에 존재하는 노드를 기억하여 문제가 생긴 노드, 해당 노드의 child, child의 child 노드
이렇게 총 3개의 노드를 이용하여 재구성한다.
만약 높이를 저장했다면 문제 노드를 찾는 과정 : O(logN)의 시간이 걸린다.
이를 재구성하기 위해 Trinode Restructure을 진행한다.
Trinode Restructure
수행 시간은 O(1)이며,
4가지 경우의 수가 존재한다.
1. R - R 형태
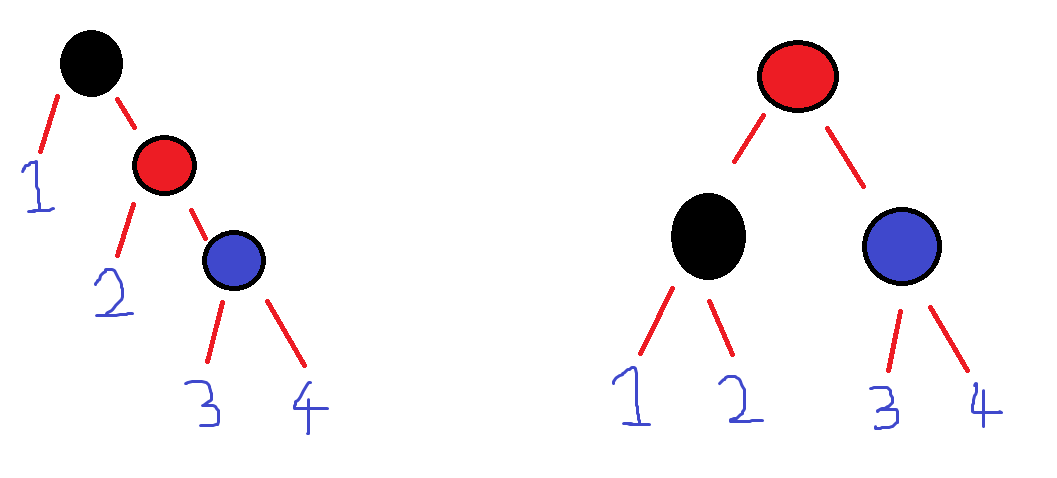
2. L - L 형태
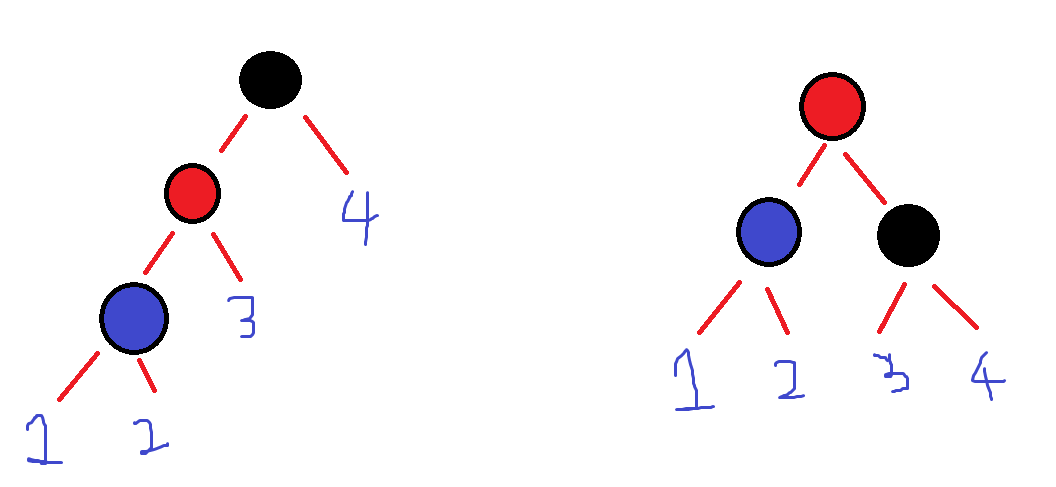
위의 두 가지 경우 모두 1번, 4번 child의 위치는 변화가 없고, 2번, 3번 child의 위치만 변경해준다.
그리고 세 노드 중 크기가 두 번째로 큰 노드를 parent로, 나머지 두 노드를 크기에 맞게 child로 연결해주면 된다.
3. L - R 형태
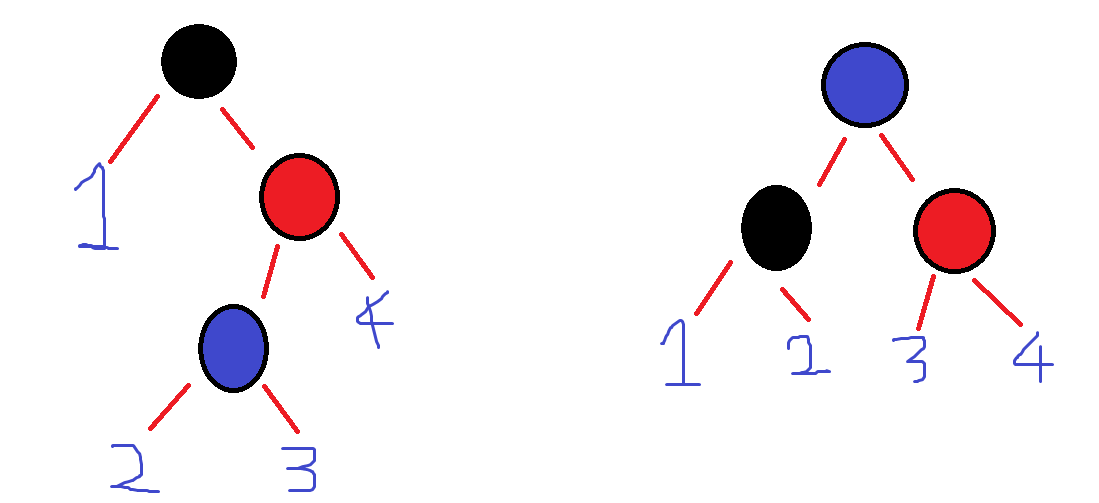
4. R - L 형태
위의 4 가지 경우 모두 세 노드 중 크기가 두 번째로 큰 노드를 parent로 삼고, 나머지 노드를 child에 연결해주었다.
1번과 2번의 경우를 single-rotation이라 부르고, 3번과 4번을 double rotation이라 부른다.
Remove
삭제연산도 BST와 마찬가지로 진행하되,
두 child의 높이 차가 1이하가 아니라면 Rebalancing을 진행한다.
마찬가지로 처음 문제가 생긴 노드를 확인하고,
이번에는 두 child를 가지고 재구성한다.
높이가 높은 child의 left와 right를 비교하여 높이가 더 높은 child를 그대로 끌고 오면 되는데,
만약 높이가 같다면 single rotation이 가능한 방향으로 진행한다.
시간 복잡도 계산
find - O(log(n))
Tree의 높이가 O(log(n))이므로
insert - O(log(n))
find에서 O(log(n))의 시간 소비, 재구성하는데 O(log(n))의 시간 소비 = O(log(n))
remove - O(log(n))
find에서 O(log(n))의 시간 소비, 재구성하는데 O(log(n))의 시간 소비 = O(log(n))
'Study > Data_Structure' 카테고리의 다른 글
| Dictionary ADT (0) | 2023.05.27 |
|---|---|
| Priority_Queue ADT (0) | 2023.05.27 |
| 완전이진트리, 포화이진트리 개념 (0) | 2023.04.16 |
Binary Search Tree
아래 그림과 같이 한 쪽으로 편향될 수 있다.
그렇기에 insert, delete, find 함수의 시간 복잡도는 최악의 경우 O(n), 가장 효율적으로는 O(log(n))이 된다.
즉, 높이 h에 따른다는 것을 알 수 있다.
Insert
root부터 해당 value 값보다 작으면 left, 크면 right로 내려가 NULL이 아닐때 까지 탐색
Delete
1. child 중 NULL이 있는 경우
-> external이 아닌 노드를 그대로 이어 붙이면 해결된다.
아래 그림은 child에 NULL이 있는 경우인 빨간색 노드를 삭제하는 경우이다.
2. 하지만 만약 child 모두 internal 이라면, 얘기가 달라진다.
아래 그림은 internal node인 빨간색을 삭제하는 경우이다.
이 경우에는 좀 복잡한데, 이는 heap의 구조와 순서를 다시 맞추어야하기 때문이다.
빨간색을 삭제함과 동시에 초록, 파랑보다 크고, 검은색보다 작은 node를 찾아야하는데,
이를 만족하는 node는 inorder-traversal을 진행하면 알 수 있다.
즉, 빨간색 노드의 right로 내려간 후, NULL이 아닐때까지 left로 내려가면 된다.
간단히 설명하자면,
- successor (가장 유사한 노드)를 먼저 찾고
- 삭제하려는 값에 덮어 씌우고
- successor를 삭제한다.
AVL Tree
BST의 구조가 Complete Binary Tree가 아니기 때문에 시간 복잡도 측면에서 O(n)이 나올 수 있다.
이를 보완하기 위해 Balanced-Binary-Tree를 고안해낸 것이 AVL Tree이다.
이는 자신의 abs(left-child의 높이 - right-child의 높이) <=1인 경우를 만족한다.
가장 깊은 노드는 x-1, x-2, x-3 ...0 으로 감소하지만
반대로 가장 얕은 노드는 x-2, x-4, x-6 ... 으로 감소한다.
즉, 길이는 약 2배 차이난다.
Insert
BST와 마찬가지로 대소 비교 후 External에 추가한다.
하지만 위로 올라가며 두 child의 높이 차가 1이하인지 확인해야 한다.
만약 두 child의 높이 차가 1보다 커지게 되면, 해당 노드를 문제가 발생한 첫 노드라고 판단한다.
그리고 지나왔던 경로에 존재하는 노드를 기억하여 문제가 생긴 노드, 해당 노드의 child, child의 child 노드
이렇게 총 3개의 노드를 이용하여 재구성한다.
만약 높이를 저장했다면 문제 노드를 찾는 과정 : O(logN)의 시간이 걸린다.
이를 재구성하기 위해 Trinode Restructure을 진행한다.
Trinode Restructure
수행 시간은 O(1)이며,
4가지 경우의 수가 존재한다.
1. R - R 형태
2. L - L 형태
위의 두 가지 경우 모두 1번, 4번 child의 위치는 변화가 없고, 2번, 3번 child의 위치만 변경해준다.
그리고 세 노드 중 크기가 두 번째로 큰 노드를 parent로, 나머지 두 노드를 크기에 맞게 child로 연결해주면 된다.
3. L - R 형태
4. R - L 형태
위의 4 가지 경우 모두 세 노드 중 크기가 두 번째로 큰 노드를 parent로 삼고, 나머지 노드를 child에 연결해주었다.
1번과 2번의 경우를 single-rotation이라 부르고, 3번과 4번을 double rotation이라 부른다.
Remove
삭제연산도 BST와 마찬가지로 진행하되,
두 child의 높이 차가 1이하가 아니라면 Rebalancing을 진행한다.
마찬가지로 처음 문제가 생긴 노드를 확인하고,
이번에는 두 child를 가지고 재구성한다.
높이가 높은 child의 left와 right를 비교하여 높이가 더 높은 child를 그대로 끌고 오면 되는데,
만약 높이가 같다면 single rotation이 가능한 방향으로 진행한다.
시간 복잡도 계산
find - O(log(n))
Tree의 높이가 O(log(n))이므로
insert - O(log(n))
find에서 O(log(n))의 시간 소비, 재구성하는데 O(log(n))의 시간 소비 = O(log(n))
remove - O(log(n))
find에서 O(log(n))의 시간 소비, 재구성하는데 O(log(n))의 시간 소비 = O(log(n))
'Study > Data_Structure' 카테고리의 다른 글
| Dictionary ADT (0) | 2023.05.27 |
|---|---|
| Priority_Queue ADT (0) | 2023.05.27 |
| 완전이진트리, 포화이진트리 개념 (0) | 2023.04.16 |